Goossips SEO : 404, 410, indexation et mises à jour
-Quelques infos sur Google (et Bing parfois) et son moteur de recherche, glanées ici et là de façon...

Quelques infos sur Google (et Bing parfois) et son moteur de recherche, glanées ici et là de façon...

Sundar Pichai, CEO de Google, dévoile sa vision de l'avenir de la recherche, marquée par...

Nouvelle tendance qui fait de plus en plus parler d’elle dans le milieu du référencement, le...
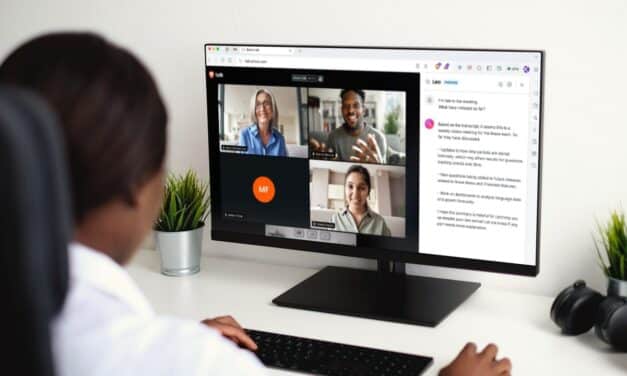
Brave annonce l'intégration de Leo, son assistant IA préservant la vie privée, sur Brave Talk, son...

Google a annoncé une série de mises à jour pour Google Workspace lors du Google Cloud Next 2024,...

Lors du Google Cloud Next 2024, la firme a dévoilé plusieurs nouveautés et avancées, notamment...
Quelques infos sur Google (et Bing parfois) et son moteur de recherche, glanées ici et là de façon...

Google pourrait bientôt changer l'accès à l'information en introduisant un modèle payant pour...

Google répète à l’envi que les propriétaires de sites doivent se concentrer sur la satisfaction...
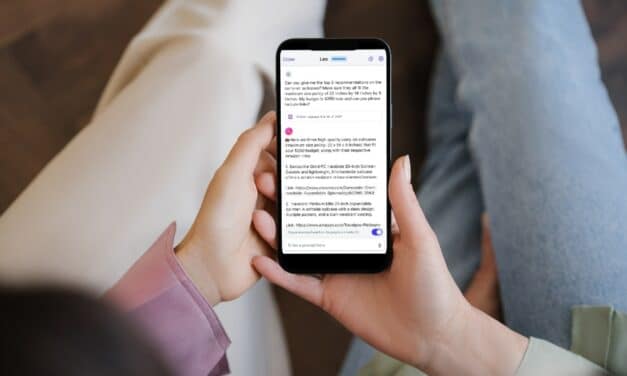
Leo, l'assistant IA intégré au navigateur Brave, est maintenant disponible sur iOS. Avec des...
Par l'intermédiaire de sa marque FormaSEO, Abondance vous propose un large choix de formations SEO en e-learning.
Si vous souhaitez une formation en présentiel, nous vous invitons à consulter le catalogue de formations SEO de notre organisme de formation alfie.







Google pourrait bientôt changer l'accès à l'information en introduisant un modèle payant pour...





Sundar Pichai, CEO de Google, dévoile sa vision de l'avenir de la recherche, marquée par...




Découvrez les termes et expressions les plus utilisées dans l'univers du référencement naturel. L'équipe Abondance vous aide à progresser ! Retrouvez ci-dessous les définitions SEO dont vous avez besoin pour mieux comprendre le référencement naturel.













